OmniToM - Benchmarking Theory of Mind in LLMs
arXiv preprint, public project page, and benchmark release for explicit belief-structure evaluation of Theory of Mind in LLMs.
OmniToM is my arXiv preprint and benchmark release for evaluating Theory of Mind in large language models through explicit belief-structure modeling rather than endpoint question answering alone.

Paper
- Title: OmniToM: Benchmarking Theory of Mind in LLMs via Explicit Belief Modeling
- Authors: Adam Bawatneh, Sagar Sapkota, Amrit Singh Bedi, Santu Karmaker, Mubarak Shah
- arXiv: arXiv:2605.26322
- PDF: arXiv PDF
- Project page: adam-12-0.github.io/omnitom-project
- Benchmark release: Adam-12-0/omnitom-benchmark
What OmniToM Measures
Most Theory of Mind benchmarks score the final answer to a social-reasoning question. OmniToM asks a deeper diagnostic question: can a model recover the underlying beliefs that each actor holds, including mistaken, inferred, or nested beliefs?
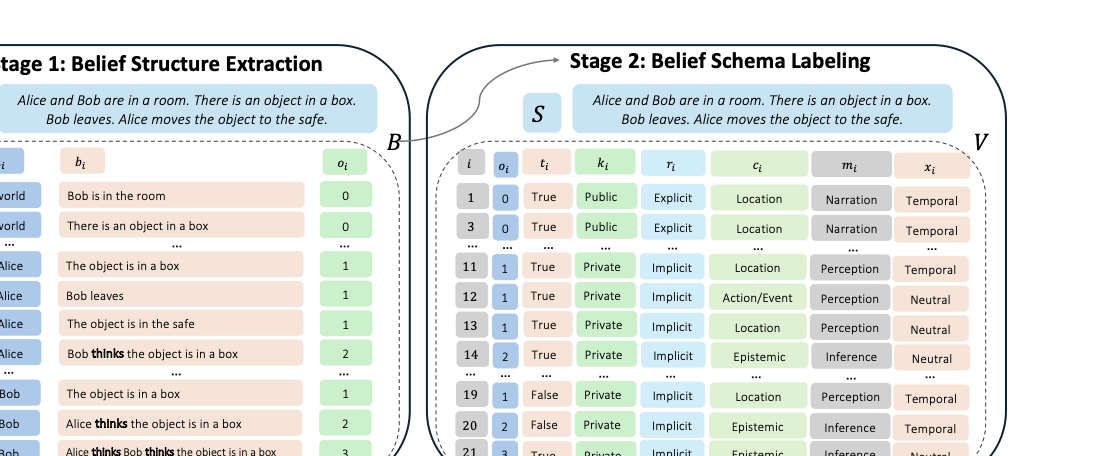
The benchmark uses a two-stage evaluation:
- Stage 1, Belief Extraction: recover the actor-specific belief propositions needed to explain a story’s social dynamics.
- Stage 2, Belief Labeling: assign each belief a seven-dimensional schema label covering recursive order, truth status, knowledge access, representation, content type, mental source, and context.
Dataset and Evaluation
- Built from 895 ToMBench-derived stories.
- Includes 22,343 labeled belief propositions.
- Uses a human-calibrated LLM-assisted annotation pipeline.
- Evaluates both open-weight and API model families under zero-shot prompting.
- Public release includes the benchmark JSONL file, Hugging Face dataset card, Croissant metadata, prompt builders, and replication scripts.
Main Finding
OmniToM reveals an actor-specific belief-tracking bottleneck. Current LLMs can often work with explicit belief structures once they are given, but struggle more when they must construct those belief structures from raw narrative text. In the paper’s zero-shot evaluation, belief labeling reaches 85.95% accuracy, while belief extraction peaks at 57.69% F1.
Why It Matters
Endpoint QA can hide whether a model actually tracked who knew what, when they knew it, and how that information became part of an actor’s mental state. OmniToM makes those intermediate representations inspectable, giving researchers a sharper tool for diagnosing social reasoning failures in LLMs.