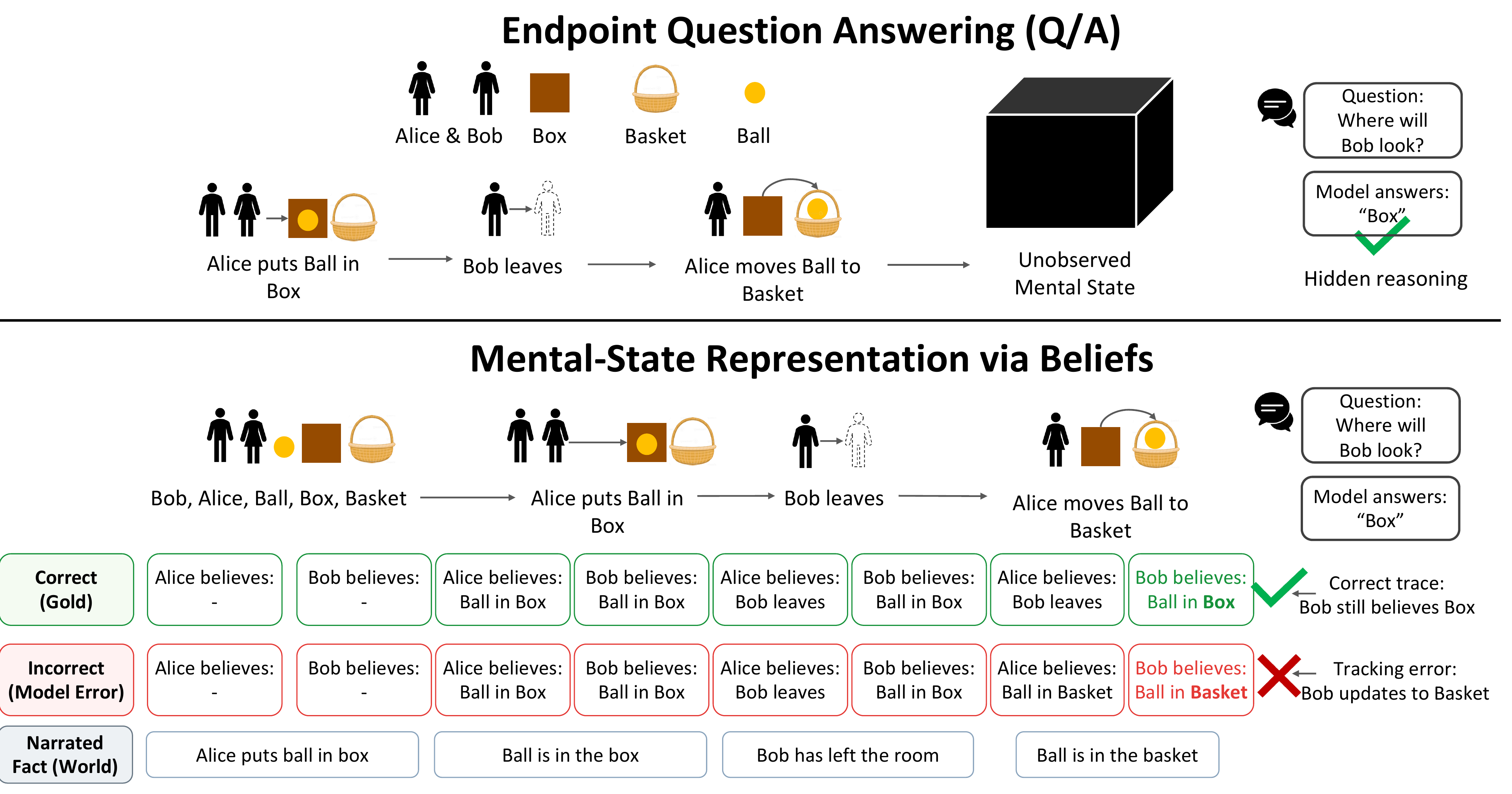
Social reasoning requires tracking how information is distributed across actors, not only what happened in the world. Existing Theory of Mind (ToM) benchmarks evaluate this ability through endpoint question answering: models are scored by whether they produce the correct final answer, leaving the underlying mental-state representation entirely unobserved. A model can answer "Where will Bob look?" correctly while failing to track the belief states that make the answer valid.
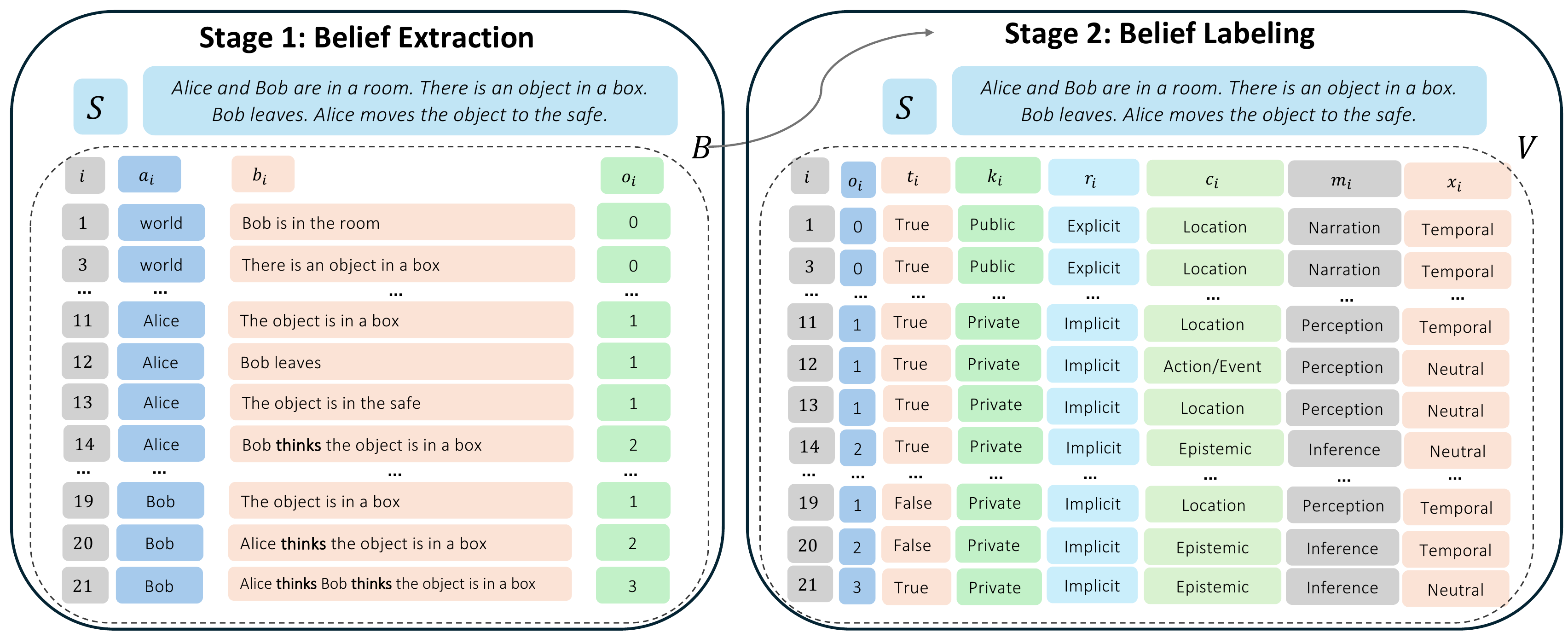
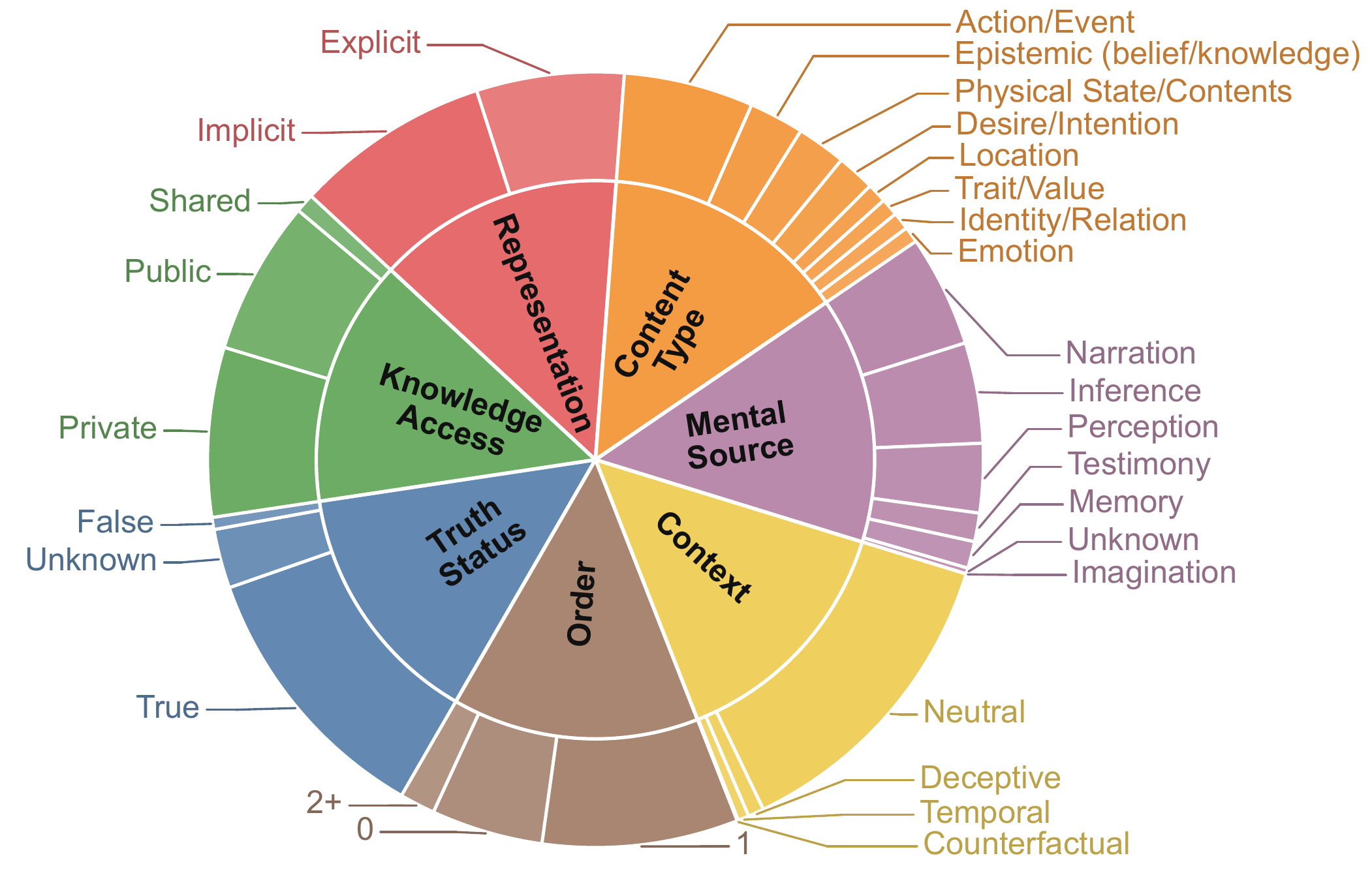
We introduce OmniToM, a benchmark that closes this gap through explicit belief-structure modeling. Rather than probing endpoints, OmniToM requires a model to reconstruct the full multi-actor belief representation of a story, then label each belief proposition along seven dimensions grounded in ATOMS, a literature-derived taxonomy of Theory of Mind abilities.
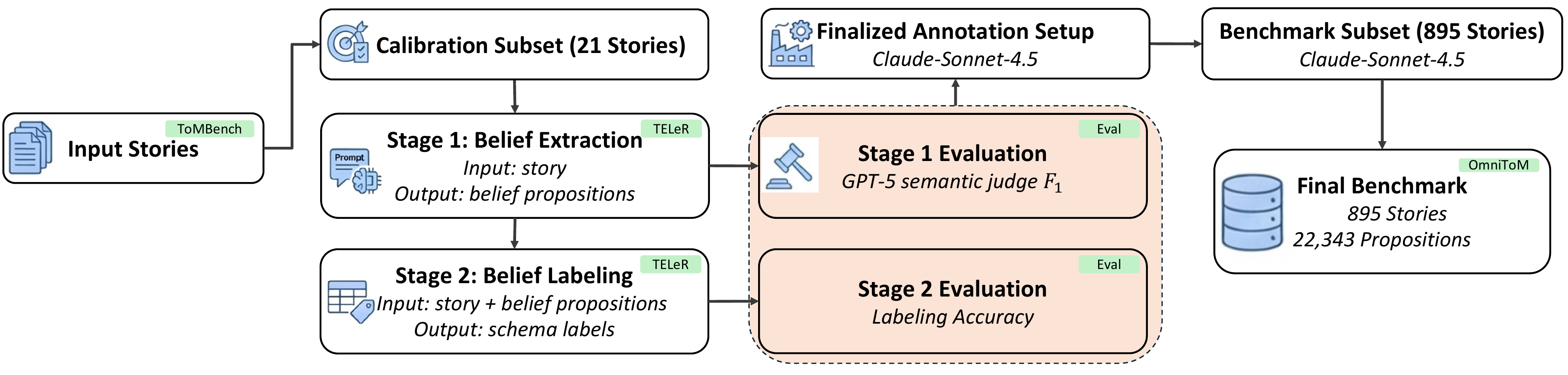
OmniToM comprises 895 stories and 22,343 labeled belief propositions developed through over 1,000 person-hours of human annotation effort. Zero-shot evaluation across nine open- and closed-source models identifies a consistent actor-specific information-tracking bottleneck: Stage 1 belief extraction peaks at 57.69% macro F1, while Stage 2 belief labeling reaches 85.95% accuracy. Errors concentrate on Knowledge Access and Representation, the dimensions that require a model to determine who could know or share a belief, and whether it is explicitly stated or inferred from context.
Seven-Dimensional Schema (grounded in ATOMS)
Order Truth Status Knowledge Access Representation Content Type Mental Source ContextOmniToM evaluates belief-structure modeling in two stages, both run under zero-shot TELeR Level 3 prompts (task directive + stepwise sub-tasks, no in-context examples):
Stage 1, Belief Extraction: Given a story, the model extracts all relevant (Actor, Belief, Order) tuples. A GPT-5 semantic judge scores extraction by precision, recall, and macro F1 over semantically matched propositions.
Stage 2, Belief Labeling: Given a story and the benchmark belief table, the model assigns a seven-dimensional schema label vector to each belief. Scored by exact-match accuracy per dimension, averaged over all propositions.
Benchmark construction required over 1,000 person-hours of human annotation to establish high-quality gold labels. From this human-calibrated foundation, a human-in-the-loop LLM-assisted pipeline was fixed and scaled to the full 895-story benchmark. Each story produces an average of 24.96 labeled belief propositions spanning world facts (Order 0, 32.6%), actor beliefs (Order 1, 57.1%), and nested beliefs (Order 2+, 10.3%).
Zero-shot TELeR Level 3 prompts. Bold = best, underline = second-best. GPT-5 is the semantic judge and is omitted from Stage 1.
| Model | Params | AST | FBT | FPT | HT | PST | SIT | SST | Overall |
|---|---|---|---|---|---|---|---|---|---|
| Closed-source models | |||||||||
| Gemini-2.5 Flash | N/A | 42.40 | 56.48 | 57.78 | 50.34 | 58.55 | 62.91 | 56.31 | 54.97 |
| GPT-5 | N/A | judge model, excluded from Stage 1 | N/A | ||||||
| Open-weight models | |||||||||
| Gemma-3 27B | 27B | 48.72 | 72.39 | 56.05 | 45.46 | 56.72 | 68.76 | 55.77 | 57.69 |
| Mistral-Small 24B | 24B | 52.97 | 54.58 | 59.79 | 48.32 | 56.97 | 66.20 | 53.17 | 56.00 |
| Mistral-Large 123B | 123B | 47.75 | 71.28 | 53.66 | 41.78 | 58.53 | 57.38 | 48.35 | 54.10 |
| Qwen3 32B | 32B | 46.88 | 57.32 | 53.38 | 41.41 | 57.25 | 56.51 | 48.67 | 51.63 |
| Llama-3.3 70B | 70B | 37.51 | 64.07 | 46.33 | 36.27 | 47.23 | 57.70 | 41.58 | 47.24 |
| Qwen3 8B | 8B | 39.12 | 50.22 | 44.21 | 37.14 | 48.36 | 47.20 | 37.60 | 43.41 |
| Llama-3.1 8B | 8B | 26.34 | 48.29 | 35.80 | 31.48 | 36.12 | 53.52 | 30.37 | 37.42 |
| Model | Order | Status | Access | Repr | CType | Source | Context | Overall |
|---|---|---|---|---|---|---|---|---|
| Closed-source models | ||||||||
| Gemini-2.5 Flash | 95.56 | 84.97 | 71.34 | 87.58 | 85.97 | 84.10 | 92.14 | 85.95 |
| GPT-5 | 95.18 | 82.72 | 66.85 | 83.42 | 79.96 | 83.02 | 88.83 | 82.85 |
| Open-weight models | ||||||||
| Mistral-Large 123B | 97.25 | 86.53 | 74.14 | 72.87 | 82.83 | 86.32 | 92.97 | 84.70 |
| Mistral-Small 24B | 95.13 | 82.22 | 74.59 | 62.79 | 76.01 | 84.82 | 91.90 | 81.06 |
| Llama-3.3 70B | 92.74 | 83.55 | 67.41 | 72.43 | 72.35 | 76.71 | 91.69 | 79.55 |
| Qwen3 32B | 96.42 | 82.43 | 73.91 | 62.45 | 71.27 | 76.84 | 90.81 | 79.16 |
| Gemma-3 27B | 96.56 | 82.44 | 71.57 | 54.33 | 73.50 | 78.72 | 92.07 | 78.46 |
| Qwen3 8B | 73.38 | 67.17 | 57.94 | 63.77 | 51.43 | 61.49 | 74.62 | 64.26 |
| Llama-3.1 8B | 71.90 | 65.59 | 56.13 | 64.40 | 48.63 | 55.18 | 76.81 | 62.66 |
Actor-specific information tracking is the core bottleneck. Models can parse social stories, but they struggle to determine which information each actor has access to, how it is communicated or inferred, and how it becomes part of that actor's mental-state representation.
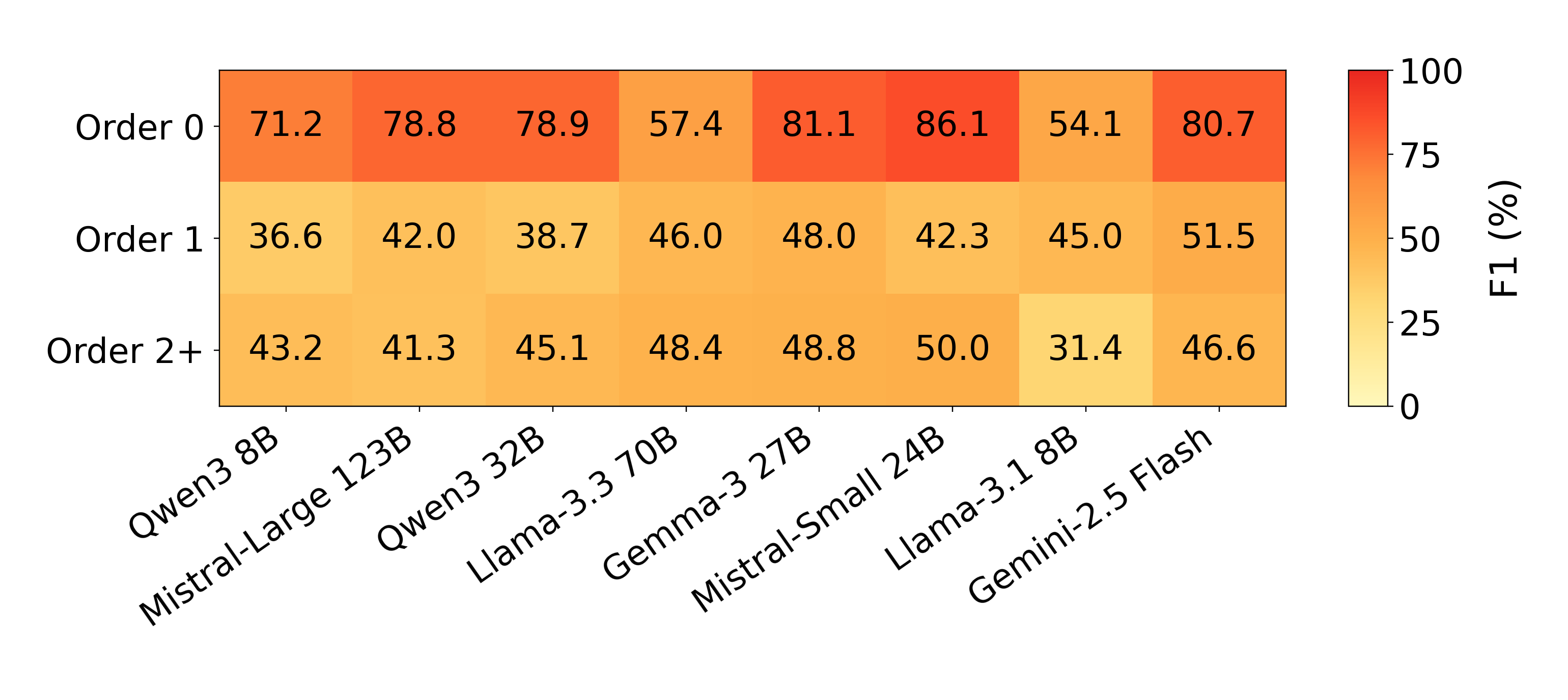
Stage 1 reveals the structural side of this bottleneck. F1 drops sharply as belief order increases: moving beyond Order 0 world facts requires the model to determine which facts each actor perceived, missed, remembered, was told, or could infer, and higher-order beliefs add a further layer of nested mental-state reasoning.
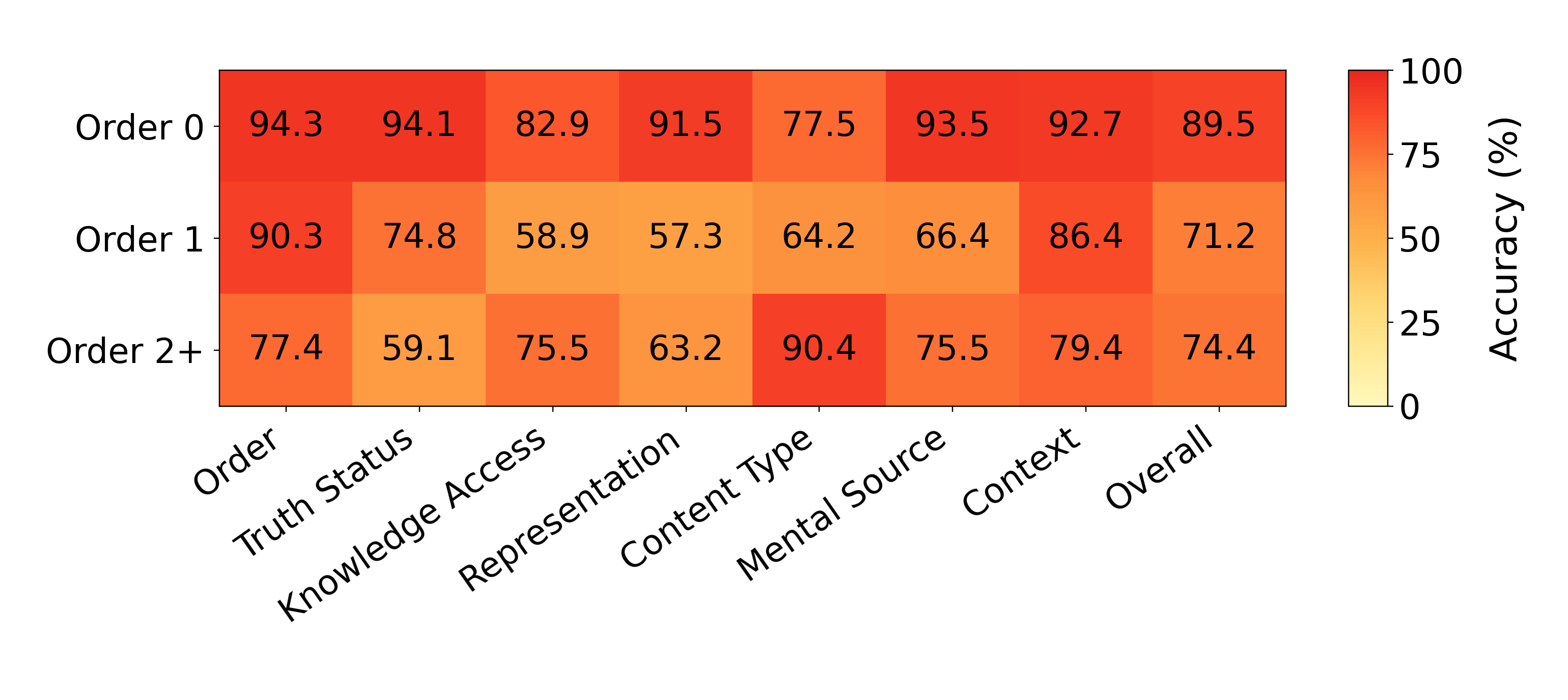
Stage 2 explains the same bottleneck at the schema-label level. Knowledge Access (56-75%) and Representation (54-88%) are the weakest dimensions across all models. The analysis by belief order shows that Order 1 actor beliefs have the lowest overall labeling accuracy (71.2%), with especially low accuracy for Knowledge Access (58.9%) and Representation (57.3%). These labels require deciding who could know or share a belief, and whether it is directly stated or inferred from perception, testimony, interaction, or context.
The gap between stages is itself diagnostic: models label provided belief propositions far better (up to 85.95%) than they extract those propositions from raw text (up to 57.69%). Current LLMs are much better at operating over an explicit belief structure once it is given than at constructing that structure directly from story text, a distinction invisible to endpoint QA benchmarks.
@article{bawatneh2026omnitom,
title = {OmniToM: Benchmarking Theory of Mind in LLMs via Explicit Belief Modeling},
author = {Bawatneh, Adam and Sapkota, Sagar and Bedi, Amrit Singh and
Karmaker, Santu and Shah, Mubarak},
journal = {arXiv preprint arXiv:2605.26322},
year = {2026}
}